
iOS 12 CoreML を試す — 機械学習で記事の分類を自動予測、モデルも自分でトレーニング!
CoreML 2.0を探る:モデルの変換やトレーニング、そして実際の製品への応用方法
前回の記事 上一篇 に続き、iOSでの機械学習の研究について、本稿では正式にCoreMLの使用に入ります。
まず歴史を簡単に説明します。Appleは2017年にCoreML(前回の記事で紹介したVisionを含む)機械学習フレームワークを発表しました。2018年にはCoreML 2.0をリリースし、性能向上に加え、カスタムCoreMLモデルのサポートも実現しました。
はじめに
もし「機械学習」という言葉を聞いたことはあっても意味がよく分からない場合、ここでは一言で簡単に説明します:
「過去の経験に基づいて、同じ出来事の未来の結果を予測する」
例えば:私は卵クレープにケチャップをかけます。何度か買ううちに、朝食店の店主の奥さんが覚えてくれて、「イケメン、ケチャップ入れる?」と聞いてきます。私が「はい」と答えると、店主の奥さんの予測は正しいです。もし「いいえ、なぜなら大根餅+卵クレープだから」と答えた場合、店主の奥さんは覚えていて、次回同じ状況で修正します。
入力データ:蛋餅、チーズ蛋餅、蛋餅+大根餅、大根餅、卵
出力データ:ケチャップをかける/かけない
モデル:女将の記憶と判断
実は機械学習については、概念や理論を知っているだけで、実際に深く理解したことはありません。間違いがあれば、どうぞご指導ください。
ここでついでにAppleの神様にお参り🛐したいです。機械学習を製品化し、基本的な概念さえわかれば操作でき、大量の知識がなくても始められるので、敷居が低くなっています。私自身もこのサンプルを実装して初めて、機械学習に触れている実感を持ち、この分野に大きな興味を持ちました。
開始
第一歩で最も重要なのは、前述した「モデル」です。モデルはどこから来るのでしょうか?
三つの方法があります:
- ネットで他人が訓練したモデルを探してCoreML形式に変換する
Awesome-CoreML-Models このGitHubプロジェクトは、多くの他人が訓練したモデルを集めています。
モデル変換については 公式サイト やオンライン資料を参照してください。
-
アップルのMachine Learning公式サイトの一番下にある「Download Core ML Models」から、アップルがトレーニングしたモデルをダウンロードできます(主に学習やテスト用です)。
-
ツールを使って自分でモデルを訓練🏆
では、何ができるのか?
-
画像認識 🏆
-
テキスト内容分類🏆
-
テキストの分割
-
言語判定
-
名詞認識
単語分割については、iOSアプリで自然言語処理を行う:NSLinguisticTagger入門を参照してください。
今日の主なポイント — 文章内容の分類+ 自分でモデルを訓練
簡単に言うと、私たちは機械に「テキスト内容」と「分類」を与えて、将来のデータを分類するように学習させます。例えば:「最新の割引を見るにはクリック!」、「1000$ショッピングクレジットをすぐに受け取る」=>「広告」;「Alanがあなたにメッセージを送信しました」、「あなたのアカウントがまもなく期限切れになります」=>「重要事項」
実際の応用:迷惑メール判別、ラベル生成、分類予測
p.s 画像認識については、何を訓練すれば良いかまだ思いついていないので、調べていません。興味がある方はこちらをご覧ください。公式で画像のGUI訓練ツールが提供されていて、とても便利です!!
必要なツール: MacOS Mojave以上 + Xcode 10
訓練ツール: BlankSpace007/TextClassiferPlayground (公式は画像用のGUI訓練ツールのみ提供しており、テキスト用は自作が必要です;これはネットの有志が提供するサードパーティーツールです)
トレーニングデータの準備:
データ構造は上図の通りで、.json と .csv ファイルをサポートしています。
訓練用のデータを準備します。ここではPhpmyadmin(Mysql)を使って訓練データをエクスポートします。
SELECT `title` AS `text`,`type` AS `label` FROM `posts` WHERE `status` = '1'
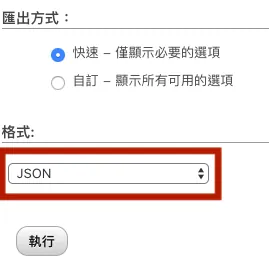
エクスポート形式をJSONフォーマットに変更する
[
{"type":"header","version":"4.7.5","comment":"PHPMyAdmin用JSONエクスポートプラグイン"},
{"type":"database","name":"db"},
{"type":"table","name":"posts","database":"db","data":
//以上削除
[
{
"label":"",
"text":""
}
]
//以下削除
}
]
ダウンロードしたJSONファイルを開き、中央のDATA構造の内容だけを残します。
訓練ツールの使用:
トレーニングツールをダウンロードしたら、TextClassifer.playground をクリックしてPlaygroundを開きます。
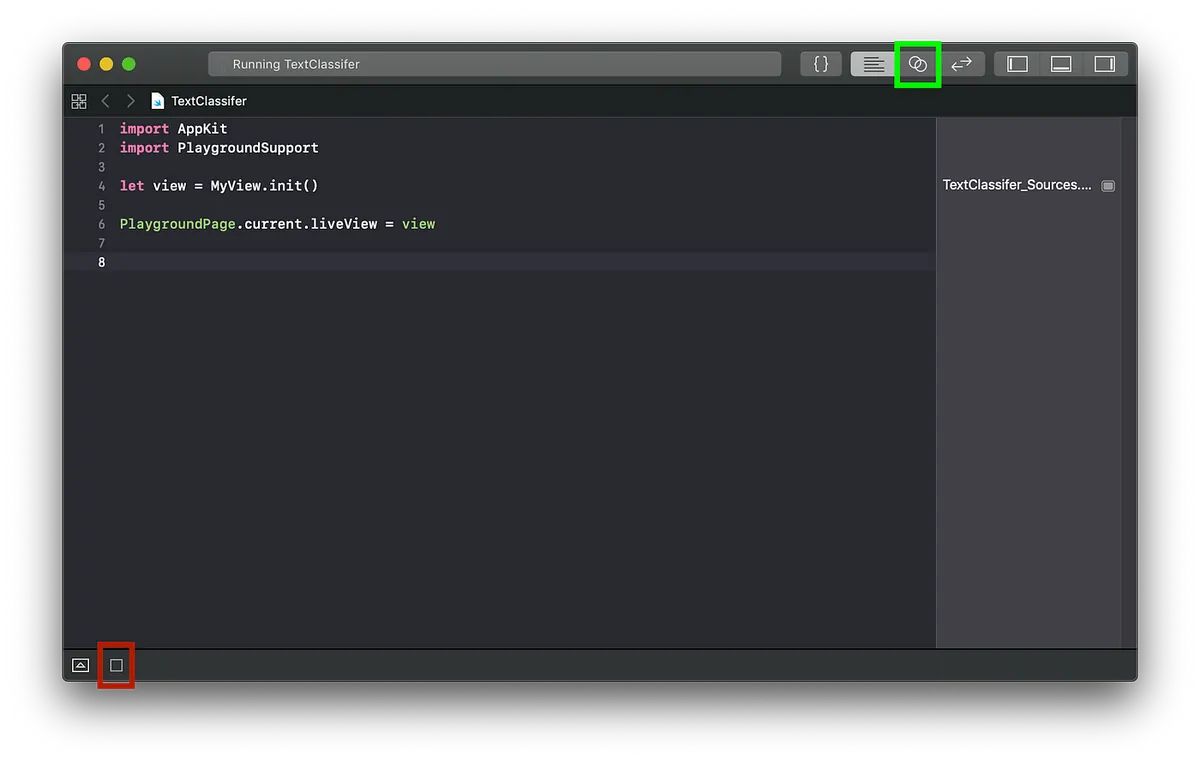
赤い枠をクリックして実行 -> 緑の枠をクリックしてView表示を切り替え
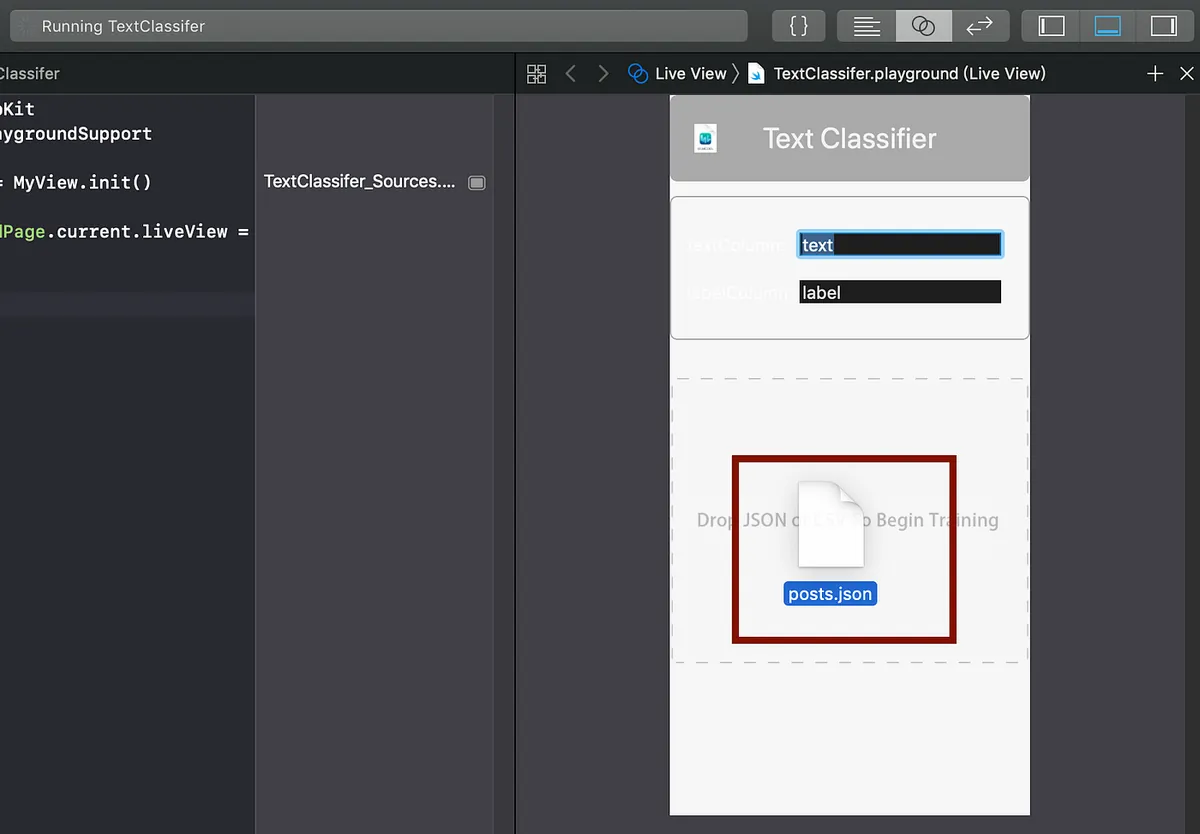
JSONファイルをGUIツールにドラッグ&ドロップする
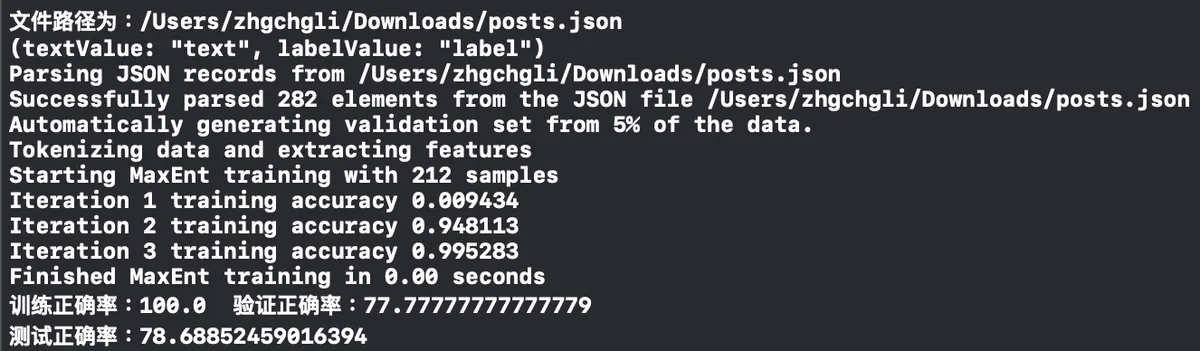
下のコンソールを開いてトレーニングの進行状況を確認してください。「テスト正解率」という行が表示されたら、モデルのトレーニングが完了したことを意味します。
データが多すぎると、パソコンの処理能力が試されます。
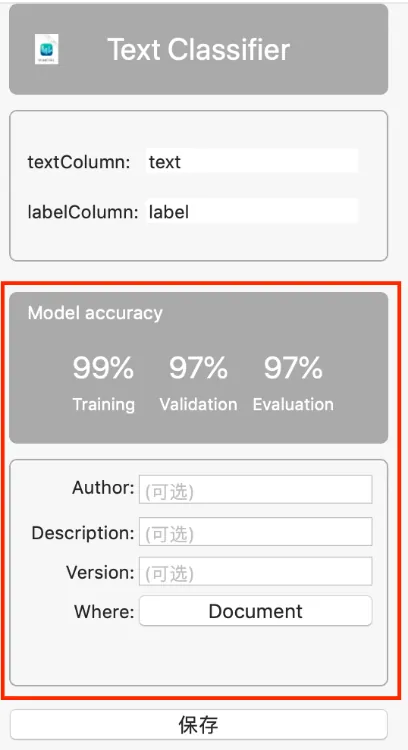
基本情報を入力した後、「保存」を押してください。
訓練済みのモデルファイルを保存する
![]()

CoreML モデルファイル
ここまででモデルの訓練は完了です!とても簡単ですよね。
具体的なトレーニング方法:
-
まず入力された文章を分かち書きします(例:「我想知道婚禮需要準備什麼」→「我想」「知道」「婚禮」「需要」「準備」「什麼」)。その後、その分類をもとに一連の機械学習処理を行います。
-
訓練データをグループ分けします。例えば、80%を訓練用に、残りの20%をテスト・検証用に使用します。
ここまででほとんどの作業が完了しました。あとはモデルファイルをiOSプロジェクトに追加し、数行のコードを書くだけです。
{: loading=”lazy” decoding=”async” width=”1200” height=”712” lqip=”data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHdpZHRoPSIxMjAwIiBoZWlnaHQ9IjcxMiI+PHJlY3Qgd2lkdGg9IjEwMCUiIGhlaWdodD0iMTAwJSIgZmlsbD0iI2VkZTJjZiIvPjwvc3ZnPg==” data-orig=”/assets/793bf2cdda0f/1*4Uc1elBmhEnQ-J8z_RIQHQ.png” }
モデルファイル(*.mlmodel)をドラッグ&ドロップまたはプロジェクトに追加する
プログラム部分:
import CoreML
//
if #available(iOS 12.0, *),let prediction = try? textClassifier().prediction(text: "予測したいテキスト内容") {
let type = prediction.label
print("私はこれだと思います...\(type)")
}
完成しました!
探索すべき課題:
-
再学習はサポートされていますか?
-
mlmodelモデルファイルを他のプラットフォームに変換できますか?
-
iOS上でモデルを訓練できますか?
以上の三点について、現在確認した情報ではすべて不可能です。
結論:
現在、実務用のアプリで記事投稿時に分類を予測するために利用しています。
訓練データは約100件しかなく、現在の予測精度は約35%で、主に実験的なものです。
— — — — —
これで簡単に、人生で初めての機械学習プロジェクトを完成しました。背景でどのように動作しているかはまだ学ぶことがたくさんありますが、このプロジェクトが皆さんの参考になれば幸いです!
参考資料: WWDC2018のCreate ML(2)
Post Mediumから変換 by ZMediumToMarkdown.


コメント