
iOS Vision framework x WWDC 24 Vision frameworkのSwift強化を発見セッション
Vision framework 機能レビュー & iOS 18 新Swift API 試用

Photo by BoliviaInteligente
テーマ

Vision Proとの関係は、ホットドッグと犬の関係と同じで、全く関係ありません。
Vision framework
Vision framework は、Appleが統合した機械学習による画像認識フレームワークで、開発者が一般的な画像認識機能を簡単かつ迅速に実装できるようにします。Vision framework は iOS 11.0+(2017年/iPhone 8)で初めてリリースされ、その後も継続的に改良され、Swift Concurrencyとの統合が進み、実行性能が向上しました。さらに、iOS 18.0 からは新しい Swift Vision framework API が提供され、Swift Concurrency の効果を最大限に発揮できるようになりました。
Vision framework の特徴
-
内蔵された多数の画像認識および動的追跡メソッド(iOS 18までに合計31種類)
-
On-Device は単にスマートフォンのチップで処理を行い、認識プロセスはクラウドサービスに依存せず、高速かつ安全です
-
APIは簡単で使いやすい
-
Apple 全プラットフォームは iOS 11.0+、iPadOS 11.0+、Mac Catalyst 13.0+、macOS 10.13+、tvOS 11.0+、visionOS 1.0+ をサポートしています。
-
数年間(2017年~現在)リリースされ、継続的に更新されています
-
Swift言語の特性を統合して計算性能を向上
6年前に少し触ったことがあります: Vision 入門 — アプリのプロフィール画像アップロード時に自動で顔を認識してトリミング (Swift)
今回はWWDC 24 Discover Swift enhancements in the Vision framework Sessionと合わせて、新しいSwiftの特徴を取り入れながら改めて復習します。
CoreML
Appleにはもう一つのフレームワークであるCoreMLもあります。これはOn-Deviceチップをベースにした機械学習フレームワークですが、自分で認識したいオブジェクトやドキュメントのモデルを訓練し、モデルをアプリに組み込んで直接使うことができます。興味がある方はぜひ試してみてください。(例:リアルタイム記事分類 、リアルタイムの迷惑メッセージ検出など)
p.s.
Vision :主に顔認識、バーコード検出、テキスト認識などの画像解析タスクに使用されます。静止画像や動画内の視覚コンテンツを処理・解析する強力なAPIを提供します。
VisionKit _:ドキュメントスキャンに関連するタスクを処理するフレームワークです。高品質なPDFや画像を生成するスキャナービューコントローラを提供します。*
Vision framework は M1 機種のシミュレーターでは動作せず、実機でのみテスト可能です。シミュレーター環境で実行すると Could not create Espresso context エラーが発生します。公式フォーラムの議論を確認しましたが、解決策は見つかりませんでした。 公式フォーラムの議論はこちら 。
手元に実際のiOS 18デバイスがないため、この記事のすべての実行結果は旧(iOS 18以前)の書き方によるものです;新しい書き方でエラーが出た場合はコメントでご指摘ください。
WWDC 2024 — VisionフレームワークのSwift強化を発見する

本記事は WWDC 24 — Discover Swift enhancements in the Vision framework セッションの共有メモと、自身の実験結果のまとめです。
はじめに — Visionフレームワークの特徴
顔認識、輪郭検出


画像内テキスト認識
iOS 18 までに、18言語をサポートしています。
// サポートされている言語一覧
if #available(iOS 18.0, *) {
print(RecognizeTextRequest().supportedRecognitionLanguages.map { "\($0.languageCode!)-\(($0.region?.identifier ?? $0.script?.identifier)!)" })
} else {
print(try! VNRecognizeTextRequest().supportedRecognitionLanguages())
}
// 実際に使用可能な認識言語はこちらが基準です。
// 実機テストでiOS 18の出力結果:
// ["en-US", "fr-FR", "it-IT", "de-DE", "es-ES", "pt-BR", "zh-Hans", "zh-Hant", "yue-Hans", "yue-Hant", "ko-KR", "ja-JP", "ru-RU", "uk-UA", "th-TH", "vi-VT", "ar-SA", "ars-SA"]
// WWDCで言及されたSwedish言語は見当たりません。まだリリースされていないか、デバイスの地域・言語設定に関連している可能性があります。
動的な動作キャプチャ


-
人や物体の動的な追跡が可能です
-
ジェスチャーキャプチャで空中署名機能を実現する
Visionの新機能 (iOS 18)— 画像評価機能(品質、特徴点)
-
入力画像にスコアを計算し、優れた写真を選びやすくします
-
スコアの計算方法は複数の要素を含み、画質だけでなく、光の状態、角度、撮影対象、記憶に残るポイントがあるかどうかも考慮されます。



WWDCでは同じ画質で、上記の3枚の画像を使って説明しました。
-
高評価の画像:構図、光、記憶に残るポイント
-
低評価の画像:主題がなく、手軽に撮ったり不注意で撮ったようなもの
-
素材の画像:技術的にはよく撮れているが、印象に残らず、素材ライブラリ用の画像のようなもの
iOS ≥ 18 新API: CalculateImageAestheticsScoresRequest
let request = CalculateImageAestheticsScoresRequest()
let result = try await request.perform(on: URL(string: "https://zhgchg.li/assets/cb65fd5ab770/1*yL3vI1ADzwlovctW5WQgJw.jpeg")!)
// 写真のスコア
print(result.overallScore)
// 素材画像と判定されたかどうか
print(result.isUtility)
Visionの新機能(iOS 18)— 体+ジェスチャーポーズの同時検出

これまでは人体のポーズと手のポーズを個別に検出するしかありませんでしたが、今回のアップデートで開発者は身体のポーズと手のポーズを同時に検出し、同じリクエストと結果として統合できるようになりました。これにより、より多くの応用機能の開発が容易になります。
iOS ≥ 18 新API: DetectHumanBodyPoseRequest
var request = DetectHumanBodyPoseRequest()
// 手のポーズも同時に検出する
request.detectsHands = true
guard let bodyPose = try await request.perform(on: image).first else { return }
// 体のポーズの関節
let bodyJoints = bodyPose.allJoints()
// 左手のポーズの関節
let leftHandJoints = bodyPose.leftHand.allJoints()
// 右手のポーズの関節
let rightHandJoints = bodyPose.rightHand.allJoints()
新しい Vision API
Apple は今回のアップデートで、新しい Swift Vision API を開発者向けに提供しました。基本的な従来の機能サポートに加え、主に Swift 6 / Swift Concurrency の特性を強化し、より高性能でより Swift らしい API 操作方法を提供しています。
Visionの使い始め方
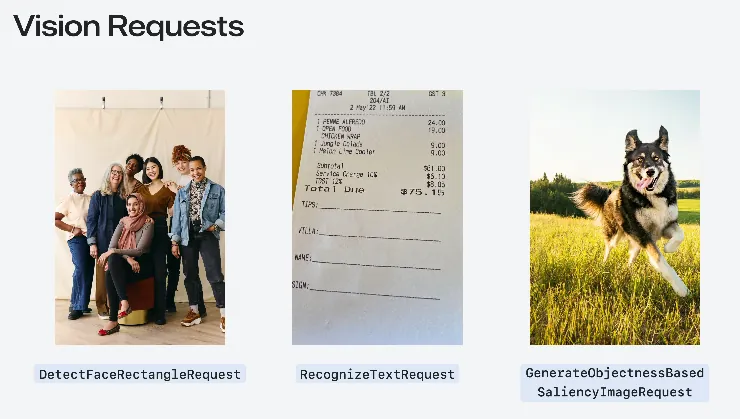
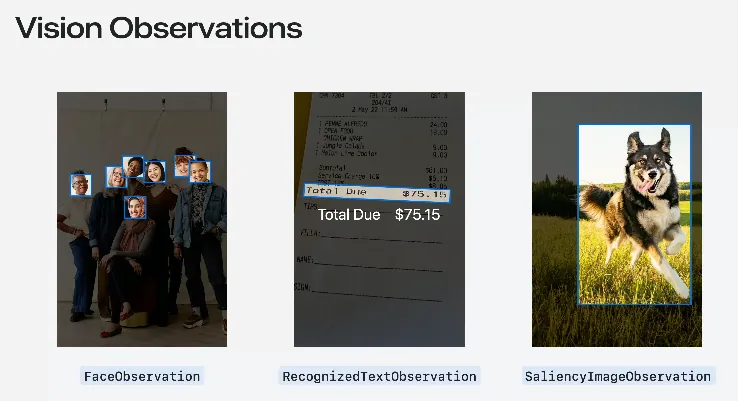
ここで講演者は再びVision frameworkの基本的な使い方を紹介しました。Appleはすでに31種類(iOS 18時点)の一般的な画像認識リクエスト「Request」と対応する「Observation」オブジェクトをラップしています。
-
Request: DetectFaceRectanglesRequest 顔領域検出リクエスト
Result: FaceObservation
以前の記事「 Vision 初探 — APP プロフィール画像アップロード 自動顔検出トリミング (Swift) 」でこのリクエストを使っています。 -
Request: RecognizeTextRequest 文字認識リクエスト
Result: RecognizedTextObservation -
Request: GenerateObjectnessBasedSaliencyImageRequest 主体物体認識リクエスト
Result: SaliencyImageObservation
全部 31 種リクエスト Request:
\| Request 用途 \| Observation 説明 \|
\|———————————————–\|——————————————————————\|
\| CalculateImageAestheticsScoresRequest
画像の美的スコアを計算します。 \| AestheticsObservation
構図や色彩などの要素を含む画像の美的評価スコアを返します。 \|
\| ClassifyImageRequest
画像内容を分類します。 \| ClassificationObservation
画像内の物体やシーンの分類ラベルと信頼度を返します。 \|
\| CoreMLRequest
Core MLモデルを使って画像を解析します。 \| CoreMLFeatureValueObservation
Core MLモデルの出力結果に基づく観察結果を生成します。 \|
\| DetectAnimalBodyPoseRequest
画像内の動物の姿勢を検出します。 \| RecognizedPointsObservation
動物の骨格点とその位置を返します。 \|
\| DetectBarcodesRequest
画像内のバーコードを検出します。 \| BarcodeObservation
バーコードのデータと種類(QRコードなど)を返します。 \|
\| DetectContoursRequest
画像内の輪郭を検出します。 \| ContoursObservation
画像で検出された輪郭線を返します。 \|
\| DetectDocumentSegmentationRequest
画像内の文書を検出・分割します。 \| RectangleObservation
文書の境界の矩形位置を返します。 \|
\| DetectFaceCaptureQualityRequest
顔のキャプチャ品質を評価します。 \| FaceObservation
顔画像の品質評価スコアを返します。 \|
\| DetectFaceLandmarksRequest
顔の特徴点を検出します。 \| FaceObservation
目や鼻などの顔の特徴点の詳細な位置を返します。 \|
\| DetectFaceRectanglesRequest
画像内の顔を検出します。 \| FaceObservation
顔の境界ボックスの位置を返します。 \|
\| DetectHorizonRequest
画像内の地平線を検出します。 \| HorizonObservation
地平線の角度と位置を返します。 \|
\| DetectHumanBodyPose3DRequest
画像内の3D人体姿勢を検出します。 \| RecognizedPointsObservation
3D人体の骨格点と空間座標を返します。 \|
\| DetectHumanBodyPoseRequest
画像内の人体姿勢を検出します。 \| RecognizedPointsObservation
人体の骨格点とその座標を返します。 \|
\| DetectHumanHandPoseRequest
画像内の手の姿勢を検出します。 \| RecognizedPointsObservation
手の骨格点とその位置を返します。 \|
\| DetectHumanRectanglesRequest
画像内の人体を検出します。 \| HumanObservation
人体の境界ボックスの位置を返します。 \|
\| DetectRectanglesRequest
画像内の矩形を検出します。 \| RectangleObservation
矩形の4つの頂点座標を返します。 \|
\| DetectTextRectanglesRequest
画像内のテキスト領域を検出します。 \| TextObservation
テキスト領域の位置と境界ボックスを返します。 \|
\| DetectTrajectoriesRequest
物体の動きの軌跡を検出・解析します。 \| TrajectoryObservation
動きの軌跡点と時間系列を返します。 \|
\| GenerateAttentionBasedSaliencyImageRequest
注意に基づく顕著性画像を生成します。 \| SaliencyImageObservation
画像内で最も注目される領域の顕著性マップを返します。 \|
\| GenerateForegroundInstanceMaskRequest
前景インスタンスマスク画像を生成します。 \| InstanceMaskObservation
前景物体のマスクを返します。 \|
\| GenerateImageFeaturePrintRequest
比較用の画像特徴プリントを生成します。 \| FeaturePrintObservation
類似度比較に使う画像の特徴プリントデータを返します。 \|
\| GenerateObjectnessBasedSaliencyImageRequest
物体の顕著性に基づく画像を生成します。 \| SaliencyImageObservation
物体の顕著性領域の顕著性マップを返します。 \|
\| GeneratePersonInstanceMaskRequest
人物インスタンスマスク画像を生成します。 \| InstanceMaskObservation
人物インスタンスのマスクを返します。 \|
\| GeneratePersonSegmentationRequest
人物セグメンテーション画像を生成します。 \| SegmentationObservation
人物のセグメンテーション二値画像を返します。 \|
\| RecognizeAnimalsRequest
画像内の動物を検出・識別します。 \| RecognizedObjectObservation
動物の種類と信頼度を返します。 \|
\| RecognizeTextRequest
画像内のテキストを検出・認識します。 \| RecognizedTextObservation
検出されたテキスト内容とその領域位置を返します。 \|
\| TrackHomographicImageRegistrationRequest
同次画像登録を追跡します。 \| ImageAlignmentObservation
画像間の同次変換行列を返し、画像登録に使用します。 \|
\| TrackObjectRequest
画像内の物体を追跡します。 \| DetectedObjectObservation
物体の画像内位置と速度情報を返します。 \|
\| TrackOpticalFlowRequest
画像内のオプティカルフローを追跡します。 \| OpticalFlowObservation
ピクセルの移動を表すオプティカルフローのベクトル場を返します。 \|
\| TrackRectangleRequest
画像内の矩形を追跡します。 \| RectangleObservation
矩形の位置、大きさ、回転角度を返します。 \|
\| TrackTranslationalImageRegistrationRequest
平行移動画像登録を追跡します。 \| ImageAlignmentObservation
画像間の平行移動変換行列を返し、画像登録に使用します。 \|
- VNを前に付けるのは旧APIの書き方です(iOS 18以前のバージョン)
講演者はいくつかのよく使われるリクエストについて言及しました。以下の通りです。
ClassifyImageRequest
入力画像を認識し、ラベル分類と信頼度を取得します。

![[遊記] 2024 九州再訪 9日間自由旅行、釜山経由→博多クルーズ入国](/assets/755509180ca8/1*f1rNoOIQbE33M9F9NmoTXg.webp)
[旅行記] 2024年 九州再訪 9日間の自由旅行、釜山経由→博多クルーズ入国
if #available(iOS 18.0, *) {
// Swiftの新機能を使った新しいAPI
let request = ClassifyImageRequest()
Task {
do {
let observations = try await request.perform(on: URL(string: "https://zhgchg.li/assets/cb65fd5ab770/1*yL3vI1ADzwlovctW5WQgJw.jpeg")!)
observations.forEach {
observation in
print("\(observation.identifier): \(observation.confidence)")
}
}
catch {
print("リクエスト失敗: \(error)")
}
}
} else {
// 以前の書き方
let completionHandler: VNRequestCompletionHandler = {
request, error in
guard error == nil else {
print("リクエスト失敗: \(String(describing: error))")
return
}
guard let observations = request.results as? [VNClassificationObservation] else {
return
}
observations.forEach {
observation in
print("\(observation.identifier): \(observation.confidence)")
}
}
let request = VNClassifyImageRequest(completionHandler: completionHandler)
DispatchQueue.global().async {
let handler = VNImageRequestHandler(url: URL(string: "https://zhgchg.li/assets/cb65fd5ab770/1*3_jdrLurFuUfNdW4BJaRww.jpeg")!, options: [:])
do {
try handler.perform([request])
}
catch {
print("リクエスト失敗: \(error)")
}
}
}
分析結果:
• outdoor(屋外): 0.75392926
• sky(空): 0.75392926
• blue_sky(青空): 0.7519531
• machine(機械): 0.6958008
• cloudy(曇り): 0.26538086
• structure(構造物): 0.15728651
• sign(標識): 0.14224191
• fence(フェンス): 0.118652344
• banner(バナー): 0.0793457
• material(素材): 0.075975396
• plant(植物): 0.054406323
• foliage(葉): 0.05029297
• light(光): 0.048126098
• lamppost(街灯): 0.048095703
• billboards(看板): 0.040039062
• art(アート): 0.03977703
• branch(枝): 0.03930664
• decoration(装飾): 0.036868922
• flag(旗): 0.036865234
....略
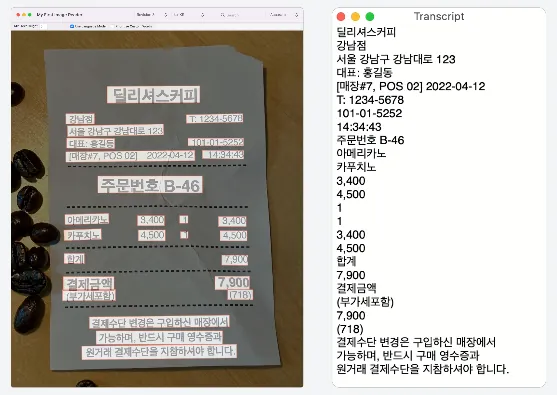
RecognizeTextRequest
画像内の文字を認識する。(別名:画像からテキストへ)
![[[遊記] 2023 東京 5 日自由行](../9da2c51fa4f2/)](/assets/755509180ca8/1*XL40lLT774PfO60rCIfnxA.webp)
if #available(iOS 18.0, *) {
// Swiftの新機能を使った新しいAPI
var request = RecognizeTextRequest()
request.recognitionLevel = .accurate
request.recognitionLanguages = [.init(identifier: "ja-JP"), .init(identifier: "en-US")] // 言語コードを指定、例:繁体字中国語
Task {
do {
let observations = try await request.perform(on: URL(string: "https://zhgchg.li/assets/9da2c51fa4f2/1*fBbNbDepYioQ-3-0XUkF6Q.jpeg")!)
observations.forEach {
observation in
let topCandidate = observation.topCandidates(1).first
print(topCandidate?.string ?? "テキストが認識されませんでした")
}
}
catch {
print("リクエスト失敗: \(error)")
}
}
} else {
// 旧APIの書き方
let completionHandler: VNRequestCompletionHandler = {
request, error in
guard error == nil else {
print("リクエスト失敗: \(String(describing: error))")
return
}
guard let observations = request.results as? [VNRecognizedTextObservation] else {
return
}
observations.forEach {
observation in
let topCandidate = observation.topCandidates(1).first
print(topCandidate?.string ?? "テキストが認識されませんでした")
}
}
let request = VNRecognizeTextRequest(completionHandler: completionHandler)
request.recognitionLevel = .accurate
request.recognitionLanguages = ["ja-JP", "en-US"] // 言語コードを指定、例:繁体字中国語
DispatchQueue.global().async {
let handler = VNImageRequestHandler(url: URL(string: "https://zhgchg.li/assets/9da2c51fa4f2/1*fBbNbDepYioQ-3-0XUkF6Q.jpeg")!, options: [:])
do {
try handler.perform([request])
}
catch {
print("リクエスト失敗: \(error)")
}
}
}
分析結果:
LE LABO 青山店
TEL:03-6419-7167
*お買い上げありがとうございます*
No: 21347
日付:2023/06/10 14.14.57
担当:
1690370
レジ:008A 1
商品名
税込上代数量税込合計
カイアック 10 EDP FB 15ML
J1P7010000S
16,800
16,800
アナザー 13 EDP FB 15ML
J1PJ010000S
10,700
10,700
リップパーム 15ML
JOWC010000S
2,000
1
合計金額
(内税額)
CARD
2,000
3点御買上げ
29,500
0
29,500
29,500
DetectBarcodesRequest
画像内のバーコードやQRコードのデータを検出する。


タイの地元民がおすすめするガチョウバーム
let filePath = Bundle.main.path(forResource: "IMG_6777", ofType: "png")! // ローカルテスト画像
let fileURL = URL(filePath: filePath)
if #available(iOS 18.0, *) {
// Swiftの新機能を使った新しいAPI
let request = DetectBarcodesRequest()
Task {
do {
let observations = try await request.perform(on: fileURL)
observations.forEach {
observation in
print("Payload: \(observation.payloadString ?? "ペイロードなし")")
print("Symbology: \(observation.symbology)")
}
}
catch {
print("リクエスト失敗: \(error)")
}
}
} else {
// 旧方式
let completionHandler: VNRequestCompletionHandler = {
request, error in
guard error == nil else {
print("リクエスト失敗: \(String(describing: error))")
return
}
guard let observations = request.results as? [VNBarcodeObservation] else {
return
}
observations.forEach {
observation in
print("Payload: \(observation.payloadStringValue ?? "ペイロードなし")")
print("Symbology: \(observation.symbology.rawValue)")
}
}
let request = VNDetectBarcodesRequest(completionHandler: completionHandler)
DispatchQueue.global().async {
let handler = VNImageRequestHandler(url: fileURL, options: [:])
do {
try handler.perform([request])
}
catch {
print("リクエスト失敗: \(error)")
}
}
}
分析結果:
Payload: 8859126000911
Symbology: VNBarcodeSymbologyEAN13
Payload: https://lin.ee/hGynbVM
Symbology: VNBarcodeSymbologyQR
Payload: http://www.hongthaipanich.com/
Symbology: VNBarcodeSymbologyQR
Payload: https://www.facebook.com/qr?id=100063856061714
Symbology: VNBarcodeSymbologyQR
RecognizeAnimalsRequest
画像内の動物と信頼度を認識する。


let filePath = Bundle.main.path(forResource: "IMG_5026", ofType: "png")! // ローカルテスト画像
let fileURL = URL(filePath: filePath)
if #available(iOS 18.0, *) {
// Swiftの新機能を使った新しいAPI
let request = RecognizeAnimalsRequest()
Task {
do {
let observations = try await request.perform(on: fileURL)
observations.forEach {
observation in
let labels = observation.labels
labels.forEach {
label in
print("検出された動物: \(label.identifier)、信頼度: \(label.confidence)")
}
}
}
catch {
print("リクエスト失敗: \(error)")
}
}
} else {
// 旧APIの書き方
let completionHandler: VNRequestCompletionHandler = {
request, error in
guard error == nil else {
print("リクエスト失敗: \(String(describing: error))")
return
}
guard let observations = request.results as? [VNRecognizedObjectObservation] else {
return
}
observations.forEach {
observation in
let labels = observation.labels
labels.forEach {
label in
print("検出された動物: \(label.identifier)、信頼度: \(label.confidence)")
}
}
}
let request = VNRecognizeAnimalsRequest(completionHandler: completionHandler)
DispatchQueue.global().async {
let handler = VNImageRequestHandler(url: fileURL, options: [:])
do {
try handler.perform([request])
}
catch {
print("リクエスト失敗: \(error)")
}
}
}
分析結果:
Detected animal: Cat with confidence: 0.77245045
その他:
-
画像内の人体を検出する:DetectHumanRectanglesRequest
-
人や動物のポーズ検出(3Dまたは2D対応):DetectAnimalBodyPoseRequest、DetectHumanBodyPose3DRequest、DetectHumanBodyPoseRequest、DetectHumanHandPoseRequest
-
物体の動きの軌跡を検出および追跡する(動画やアニメーションの異なるフレームで):DetectTrajectoriesRequest、TrackObjectRequest、TrackRectangleRequest
iOS ≥ 18 アップデートのハイライト:
VN*Request -> *Request (例:VNDetectBarcodesRequest -> DetectBarcodesRequest)
VN*Observation -> *Observation (例:VNRecognizedObjectObservation -> RecognizedObjectObservation)
VNRequestCompletionHandler -> async/await
VNImageRequestHandler.perform([VN*Request]) -> *Request.perform()
WWDCの例
WWDC公式動画では、スーパーマーケットの商品スキャナーを例に挙げています。
まずほとんどの商品にはスキャン可能なバーコードがあります


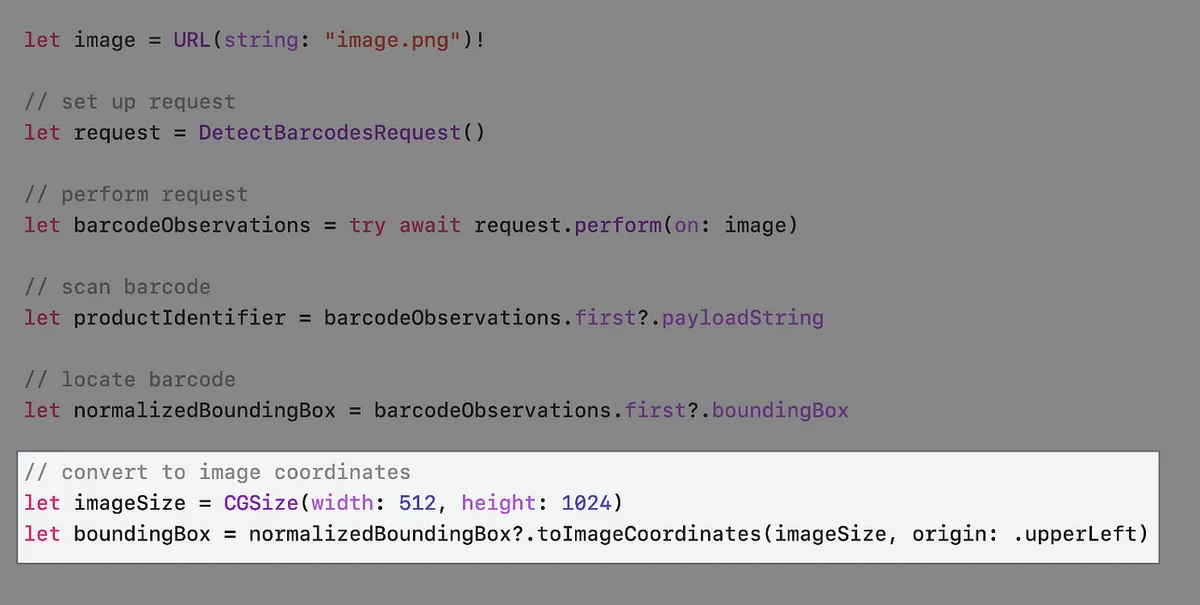
observation.boundingBox からバーコードの位置を取得できますが、一般的な UIView 座標系とは異なり、BoundingBox の相対位置の起点は左下で、値の範囲は0〜1の間です。
let filePath = Bundle.main.path(forResource: "IMG_6785", ofType: "png")! // ローカルテスト画像
let fileURL = URL(filePath: filePath)
if #available(iOS 18.0, *) {
// Swiftの新機能を使った新しいAPI
var request = DetectBarcodesRequest()
request.symbologies = [.ean13] // EAN13バーコードのみをスキャンする場合は直接指定してパフォーマンス向上
Task {
do {
let observations = try await request.perform(on: fileURL)
if let observation = observations.first {
DispatchQueue.main.async {
self.infoLabel.text = observation.payloadString
// マーク用の色レイヤー
let colorLayer = CALayer()
// iOS >=18 新しい座標変換API toImageCoordinates
// 未検証で、実際にはContentMode = AspectFitのオフセット計算が必要かも:
colorLayer.frame = observation.boundingBox.toImageCoordinates(self.baseImageView.frame.size, origin: .upperLeft)
colorLayer.backgroundColor = UIColor.red.withAlphaComponent(0.5).cgColor
self.baseImageView.layer.addSublayer(colorLayer)
}
print("BoundingBox: \(observation.boundingBox.cgRect)")
print("Payload: \(observation.payloadString ?? "No payload")")
print("Symbology: \(observation.symbology)")
}
}
catch {
print("Request failed: \(error)")
}
}
} else {
// 旧APIの書き方
let completionHandler: VNRequestCompletionHandler = {
request, error in
guard error == nil else {
print("Request failed: \(String(describing: error))")
return
}
guard let observations = request.results as? [VNBarcodeObservation] else {
return
}
if let observation = observations.first {
DispatchQueue.main.async {
self.infoLabel.text = observation.payloadStringValue
// マーク用の色レイヤー
let colorLayer = CALayer()
colorLayer.frame = self.convertBoundingBox(observation.boundingBox, to: self.baseImageView)
colorLayer.backgroundColor = UIColor.red.withAlphaComponent(0.5).cgColor
self.baseImageView.layer.addSublayer(colorLayer)
}
print("BoundingBox: \(observation.boundingBox)")
print("Payload: \(observation.payloadStringValue ?? "No payload")")
print("Symbology: \(observation.symbology.rawValue)")
}
}
let request = VNDetectBarcodesRequest(completionHandler: completionHandler)
request.symbologies = [.ean13] // EAN13バーコードのみをスキャンする場合は直接指定してパフォーマンス向上
DispatchQueue.global().async {
let handler = VNImageRequestHandler(url: fileURL, options: [:])
do {
try handler.perform([request])
}
catch {
print("Request failed: \(error)")
}
}
}
iOS ≥ 18 アップデートのハイライト:
// iOS >=18 新しい座標変換API toImageCoordinates
observation.boundingBox.toImageCoordinates(CGSize, origin: .upperLeft)
// https://developer.apple.com/documentation/vision/normalizedpoint/toimagecoordinates(from:imagesize:origin:)
ヘルパー:
// ChatGPT 4oによって生成
// 画像がImageViewでContentMode = AspectFitに設定されているため
// Fitによってできる上下の空白のオフセットを計算する必要がある
func convertBoundingBox(_ boundingBox: CGRect, to view: UIImageView) -> CGRect {
guard let image = view.image else {
return .zero
}
let imageSize = image.size
let viewSize = view.bounds.size
let imageRatio = imageSize.width / imageSize.height
let viewRatio = viewSize.width / viewSize.height
var scaleFactor: CGFloat
var offsetX: CGFloat = 0
var offsetY: CGFloat = 0
if imageRatio > viewRatio {
// 画像は幅方向にフィットしている
scaleFactor = viewSize.width / imageSize.width
offsetY = (viewSize.height - imageSize.height * scaleFactor) / 2
}
else {
// 画像は高さ方向にフィットしている
scaleFactor = viewSize.height / imageSize.height
offsetX = (viewSize.width - imageSize.width * scaleFactor) / 2
}
let x = boundingBox.minX * imageSize.width * scaleFactor + offsetX
let y = (1 - boundingBox.maxY) * imageSize.height * scaleFactor + offsetY
let width = boundingBox.width * imageSize.width * scaleFactor
let height = boundingBox.height * imageSize.height * scaleFactor
return CGRect(x: x, y: y, width: width, height: height)
}
出力結果
BoundingBox: (0.5295758928571429, 0.21408638121589782, 0.0943080357142857, 0.21254415360708087)
Payload: 4710018183805
Symbology: VNBarcodeSymbologyEAN13
一部の商品にはバーコードがなく、例えばバラ売りの果物には商品ラベルのみがあります

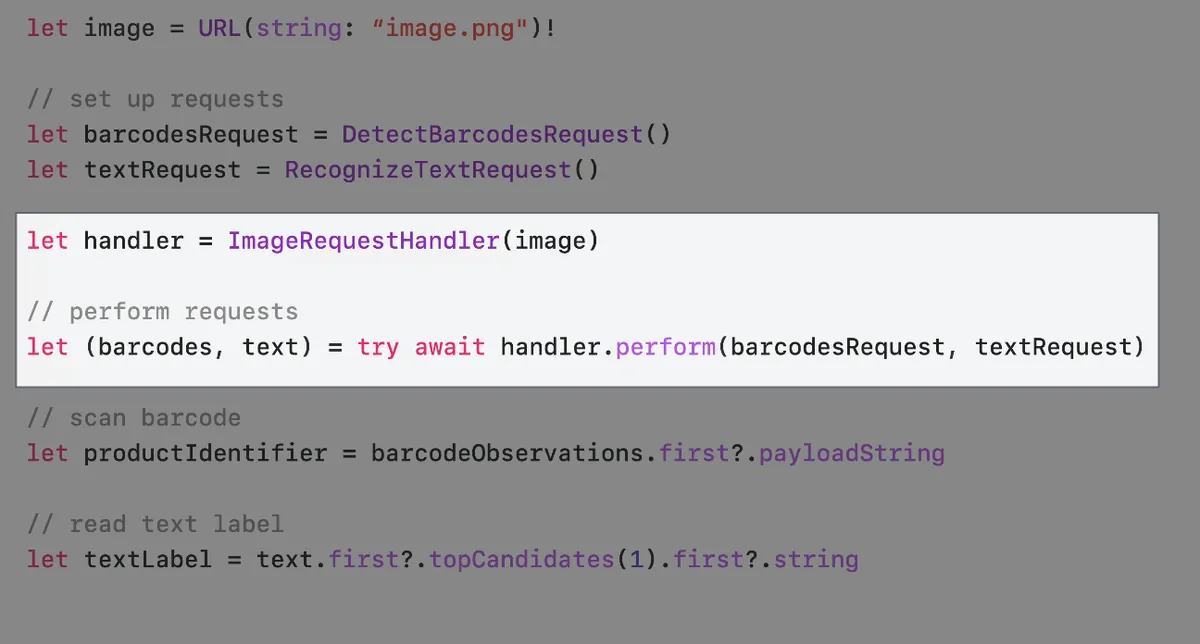
そのため、私たちのスキャナーもテキストラベルのスキャンに対応する必要があります。
let filePath = Bundle.main.path(forResource: "apple", ofType: "jpg")! // ローカルテスト画像
let fileURL = URL(filePath: filePath)
if #available(iOS 18.0, *) {
// Swiftの新機能を使った新しいAPI
var barcodesRequest = DetectBarcodesRequest()
barcodesRequest.symbologies = [.ean13] // EAN13バーコードのみスキャンする場合は指定してパフォーマンス向上
var textRequest = RecognizeTextRequest()
textRequest.recognitionLanguages = [.init(identifier: "zh-Hnat"), .init(identifier: "en-US")]
Task {
do {
let handler = ImageRequestHandler(fileURL)
// パラメータパック構文で全リクエストの完了を待つ必要がある
// let (barcodesObservation, textObservation, ...) = try await handler.perform(barcodesRequest, textRequest, ...)
let (barcodesObservation, textObservation) = try await handler.perform(barcodesRequest, textRequest)
if let observation = barcodesObservation.first {
DispatchQueue.main.async {
self.infoLabel.text = observation.payloadString
// マーク用の色レイヤー
let colorLayer = CALayer()
// iOS >=18 新しい座標変換API toImageCoordinates
// 未検証で、実際にはContentMode = AspectFitのオフセット計算が必要な可能性あり
colorLayer.frame = observation.boundingBox.toImageCoordinates(self.baseImageView.frame.size, origin: .upperLeft)
colorLayer.backgroundColor = UIColor.red.withAlphaComponent(0.5).cgColor
self.baseImageView.layer.addSublayer(colorLayer)
}
print("BoundingBox: \(observation.boundingBox.cgRect)")
print("Payload: \(observation.payloadString ?? "ペイロードなし")")
print("Symbology: \(observation.symbology)")
}
textObservation.forEach {
observation in
let topCandidate = observation.topCandidates(1).first
print(topCandidate?.string ?? "テキスト認識なし")
}
}
catch {
print("リクエスト失敗: \(error)")
}
}
} else {
// 以前の書き方
let barcodesCompletionHandler: VNRequestCompletionHandler = {
request, error in
guard error == nil else {
print("リクエスト失敗: \(String(describing: error))")
return
}
guard let observations = request.results as? [VNBarcodeObservation] else {
return
}
if let observation = observations.first {
DispatchQueue.main.async {
self.infoLabel.text = observation.payloadStringValue
// マーク用の色レイヤー
let colorLayer = CALayer()
colorLayer.frame = self.convertBoundingBox(observation.boundingBox, to: self.baseImageView)
colorLayer.backgroundColor = UIColor.red.withAlphaComponent(0.5).cgColor
self.baseImageView.layer.addSublayer(colorLayer)
}
print("BoundingBox: \(observation.boundingBox)")
print("Payload: \(observation.payloadStringValue ?? "ペイロードなし")")
print("Symbology: \(observation.symbology.rawValue)")
}
}
let textCompletionHandler: VNRequestCompletionHandler = {
request, error in
guard error == nil else {
print("リクエスト失敗: \(String(describing: error))")
return
}
guard let observations = request.results as? [VNRecognizedTextObservation] else {
return
}
observations.forEach {
observation in
let topCandidate = observation.topCandidates(1).first
print(topCandidate?.string ?? "テキスト認識なし")
}
}
let barcodesRequest = VNDetectBarcodesRequest(completionHandler: barcodesCompletionHandler)
barcodesRequest.symbologies = [.ean13] // EAN13バーコードのみスキャンする場合は指定してパフォーマンス向上
let textRequest = VNRecognizeTextRequest(completionHandler: textCompletionHandler)
textRequest.recognitionLevel = .accurate
textRequest.recognitionLanguages = ["en-US"]
DispatchQueue.global().async {
let handler = VNImageRequestHandler(url: fileURL, options: [:])
do {
try handler.perform([barcodesRequest, textRequest])
}
catch {
print("リクエスト失敗: \(error)")
}
}
}
出力結果:
94128s
オーガニック
ピンクレディ®
USh産
iOS ≥ 18 アップデートのハイライト:
let handler = ImageRequestHandler(fileURL)
// パラメータパック構文で、すべてのリクエストが完了するのを待ってから結果を使用します。
// let (barcodesObservation, textObservation, ...) = try await handler.perform(barcodesRequest, textRequest, ...)
let (barcodesObservation, textObservation) = try await handler.perform(barcodesRequest, textRequest)
iOS ≥ 18 performAll( )?changes=latest_minor){:target=”_blank”} メソッド

前の perform(barcodesRequest, textRequest) はバーコードスキャンとテキストスキャンの処理で、両方のリクエストが完了するまで次の処理に進めませんでした。iOS 18からは新しい performAll() メソッドが提供され、レスポンス方式がストリームに変わり、いずれかのリクエスト結果を受け取ったらすぐに対応処理が可能になります。
if #available(iOS 18.0, *) {
// Swiftの新機能を使用した新しいAPI
var barcodesRequest = DetectBarcodesRequest()
barcodesRequest.symbologies = [.ean13] // EAN13バーコードのみをスキャンする場合は指定してパフォーマンス向上
var textRequest = RecognizeTextRequest()
textRequest.recognitionLanguages = [.init(identifier: "zh-Hnat"), .init(identifier: "en-US")]
Task {
let handler = ImageRequestHandler(fileURL)
let observation = handler.performAll([barcodesRequest, textRequest] as [any VisionRequest])
for try await result in observation {
switch result {
case .detectBarcodes(_, let barcodesObservation):
if let observation = barcodesObservation.first {
DispatchQueue.main.async {
self.infoLabel.text = observation.payloadString
// 色付きレイヤーのマーク
let colorLayer = CALayer()
// iOS >=18 新しい座標変換API toImageCoordinates
// 未検証、実際にはContentMode = AspectFitのオフセット計算が必要かもしれません:
colorLayer.frame = observation.boundingBox.toImageCoordinates(self.baseImageView.frame.size, origin: .upperLeft)
colorLayer.backgroundColor = UIColor.red.withAlphaComponent(0.5).cgColor
self.baseImageView.layer.addSublayer(colorLayer)
}
print("BoundingBox: \(observation.boundingBox.cgRect)")
print("Payload: \(observation.payloadString ?? "No payload")")
print("Symbology: \(observation.symbology)")
}
case .recognizeText(_, let textObservation):
textObservation.forEach {
observation in
let topCandidate = observation.topCandidates(1).first
print(topCandidate?.string ?? "認識されたテキストなし")
}
default:
print("認識されない結果: \(result)")
}
}
}
}
Swift Concurrencyで最適化する


ある画像ウォールリストがあり、各画像から自動的に対象物をトリミングする必要があるとします。この場合、Swift Concurrencyを活用して読み込み効率を向上させることができます。
元の書き方
func generateThumbnail(url: URL) async throws -> UIImage {
let request = GenerateAttentionBasedSaliencyImageRequest()
let saliencyObservation = try await request.perform(on: url)
return cropImage(url, to: saliencyObservation.salientObjects)
}
func generateAllThumbnails() async throws {
for image in images {
image.thumbnail = try await generateThumbnail(url: image.url)
}
}
一度に一つだけ実行するため、効率と性能が遅い。
最適化 (1) — TaskGroup 同時実行
func generateAllThumbnails() async throws {
try await withThrowingDiscardingTaskGroup { taskGroup in
for image in images {
image.thumbnail = try await generateThumbnail(url: image.url)
}
}
}
各タスクをTaskGroupの並行処理に追加します。
問題:画像認識やスクリーンショット操作は非常にメモリとパフォーマンスを消費します。無制限に並行タスクを増やすと、ユーザーの動作が重くなったり、OOMクラッシュの原因となる可能性があります。
最適化 (2) — TaskGroup Concurrency + 並行数の制限
func generateAllThumbnails() async throws {
try await withThrowingDiscardingTaskGroup {
taskGroup in
// 最大同時実行数は5を超えない
let maxImageTasks = min(5, images.count)
// まず5つのタスクを作成
for index in 0..<maxImageTasks {
taskGroup.addTask {
image[index].thumbnail = try await generateThumbnail(url: image[index].url)
}
}
var nextIndex = maxImageTasks
for try await _ in taskGroup {
// taskGroup内のタスクが完了した時...
// インデックスが終端か確認
if nextIndex < images.count {
let image = images[nextIndex]
// タスクを順次追加(最大5つを維持)
taskGroup.addTask {
image.thumbnail = try await generateThumbnail(url: image.url)
}
nextIndex += 1
}
}
}
}
既存のVisionアプリを更新する


-
Visionは、ニューラルエンジン搭載デバイスで一部リクエストに対するCPUとGPUのサポートを廃止します。これらのデバイスではニューラルエンジンが最も高性能な選択肢です。
supportedComputeDevices()APIで確認できます。 -
すべてのVNプレフィックスを削除
VNXXRequest,VNXXXObservation→Request,Observation -
async/awaitを使って元のVNRequestCompletionHandlerを置き換えます。
-
直接
*Request.perform()を使用し、従来のVNImageRequestHandler.perform([VN*Request])を置き換えます。
まとめ
-
Swift言語の特性に合わせて新たに設計されたAPI
-
新機能やメソッドはすべてSwift専用で、iOS 18以降で利用可能です
-
新しい画像美学評価機能、身体+手のジェスチャー追跡
ありがとう!

KKday 募集のお知らせ

👉👉👉今回の勉強会の共有はKKdayアプリチームの週次技術共有活動に由来します。現在チームではSenior iOS Engineerを積極的に募集しています。興味のある方はぜひご応募ください。👈👈👈
参考資料
VisionフレームワークのSwift強化を発見する
Vision FrameworkのAPIは、並行処理などの最新のSwift機能を活用するように再設計されており、さまざまなVisionアルゴリズムをアプリにより簡単かつ高速に統合できます。更新されたAPIを紹介し、サンプルコードやベストプラクティスを共有して、より少ないコーディングでこのフレームワークの利点を活用できるようにします。また、新機能の画像美学評価と全身姿勢検出についても実演します。
章節
-
0:00 — イントロダクション
-
1:07 — 新しいVision API
-
1:47 — Visionの使い方を始める
-
8:59 — Swift Concurrencyで最適化
-
11:05 — 既存のVisionアプリを更新する
-
13:46 — Visionの新機能
Vision framework Apple Developer Documentation
-
Post は ZMediumToMarkdown によって Medium から変換されました。



コメント